머신러닝의 대표 앙상블
머신러닝의 대표 앙상블! ‘랜덤 포레스트’에 대하여
① 머신러닝 편, 정*은 님
-
데이터를 분류하는 모델을 여러 개 생성하고, 그 예측을 결합함으로써 신뢰도가 높은 예측 값을 만들어내는 앙상블 기법. 그 중에서도 가장 대표적인 앙상블 기법은 바로 ‘랜덤 포레스트’입니다.
사회학 전공, 비전공자 출신으로 커넥to 데이터사이언스로 함께하고 있는 수강생 정*은 님. 올해 치룬 빅데이터 분석기사 시험에서 랜덤 포레스트에 대해 뼈아픈 기억을 갖고 있다고 하는데요. 커넥to 과정에서는 어떻게 차근차근 체득해나가고 있는지, 함께 살펴볼까요?
Q. 안녕하세요. 자기소개 부탁드립니다.
안녕하세요, 커넥to 데이터 사이언스 수강생 정*은입니다. 대학에서는 사회학과 문화콘텐츠를 복수전공했습니다. 대학 때 사회통계론이라는 전공필수 수업을 들으면서 통계에 대한 관심을 갖게 됐고, 파이썬을 활용한 데이터 분석에 흥미가 생겨 커넥to에 지원했습니다. 전공자와 비교해 부족한 데이터 사이언스 관련 이론과 프로젝트 경험을 커넥to에서 쌓을 수 있을 것 같아 많은 기대가 됩니다.

△ 커넥to 데이터 사이언스 정*은 님
Q. 오늘 소개할 데이터 사이언스 관련 주제는 ‘랜덤 포레스트’라 하셨는데, 어떤 개념인가요?
랜덤 포레스트는 앙상블 기법*의 대표적인 알고리즘입니다. (*앙상블 기법 : 여러 개의 심플한 모델을 생성하고 각각의 예측을 결합함으로써 단일 분류기보다 신뢰성이 높은 최종 예측 값을 얻어내는 기법)
커넥to 데이터 사이언스에서는 지금 데이터 분석 과정 중 ‘머신러닝’을 배우고 있습니다. 머신러닝은 간단히 말하면, 기계가 데이터로부터 학습을 한 후, 새롭게 들어온 데이터를 정확히 처리할 수 있는 능력을 말합니다. 그 중에도 엄청나게 다양한 알고리즘이 있는데, 그중 하나가 의사결정 나무(Decision Tree)라고 합니다. 큰 나무가 가지를 쳐 나가며 결정하는 것이죠.
예를 들어서, 저는 블로그에 이 주제를 설명하면서 ‘여행자가 여행을 떠날 때 여행 보험을 구입할지 말지를 예측하는 모델’을 실습해봤습니다. 성별이나 기존 구매이력 등 여러 데이터를 이를 종합해서 이 사람이 보험을 살지말지 여부를 예측해봤죠.
그 모델을 만드는 알고리즘으로 의사결정 나무가 쓰일 수 있습니다. 그 나무들이 100 그루, 200 그루 모인 것을 랜덤 포레스트(Random forest)라고 합니다. 그래서 한 나무만 있으면 한 케이스밖에 없는 건데, 그 나무가 늘어나서 그것들의 평균을 낸다거나, 가장 성능이 좋은 나무를 고르는 거죠. 할 수 있는 소스를 얻는 알고리즘이다 보니 성능이 좋고 예측 성능이 올라간다는 장점이 있어서 많이 쓰이고 있습니다. 랜덤 포레스트는 지도학습 중 ‘분류, 회귀’ 두 가지 관점에서 모두 쓰일 수 있어 굉장히 효율적이에요.
Q. 지도학습의 분류와 회귀는 각각 어떻게 다른가요?
우선 머신러닝은 지도학습과 비지도학습으로 나뉩니다. 간단히 설명해서, 지도학습은 답이 정해져 있어서 이를 예측하는 것이고, 비지도학습은 답이 정해져있는 건 아닌데 특성을 보고 묶어서 군집화하는 식으로 쓰입니다. 현업에서는 명확히 분리해서 사용하기보다는 다 합쳐서 쓰인다고 해요.
또, 지도학습은 분류와 회귀로 나뉘는데요. 구하는 답이 명사라면 분류, 답이 숫자식이라면 회귀입니다. 쉽게 이야기해서 집값을 예측한다면 회귀분석, 어떤 꽃의 품종을 맞춘다 하면 분류가 되는 것이죠.
Q. ‘랜덤 포레스트’ 라는 주제를 선정한 과정과 이유를 설명해 주세요.
올해 6월, 빅데이터 분석기사 1회차 시험을 응시했었어요. 필기를 붙고, 실기 시험을 치르게 되었는데 코드만 외워가서인지 떨어졌어요. 그 당시 주변 사람들이 랜덤 포레스트만 알고 가면 된다고 해서, 랜덤 포레스트가 제 기억에 강력히 남아있는 알고리즘입니다.
그 시험을 준비하면서 어렴풋이 공부했었는데, 이곳에서 머신러닝 수업을 들으면서 직접 코드를 짜고 결과를 내보게 됐습니다. 요즘은 ‘그 때 공부했던 게 이거였구나’ 하면서 이제야 이해하고 있죠. 그때는 이해가 잘 가지 않았던 개념이었는데 지금은 직접 다뤄보니 익숙해졌습니다. 이 주제를 선정한 데엔 이런 사연이 있었습니다. (웃음)
Q. 커넥to에서 데이터 분석가로서는 어떤 가치관을 만들어가고 있나요?
잘 짜여진 커리큘럼을 따라가는것만으로도 벅찬 것이 사실인데요. 그럼에도 한 가지 배운 것은 ‘좋은 결과를 만들어내려면 데이터를 수집할 때부터 좋은 자료가 수집돼야 하고, 전처리, 가공하는 과정부터 중요하게 여겨야 한다’라는 점입니다. 어떤 모델의 파라미터, 또는 하이퍼 파라미터를 조정한다고 해서 예측 성능이 드라마틱하게 좋아지는 경우는 없다고 하시더라구요. 수집 단계부터 가볍게 여기지 않고, 인사이트를 얻을때 까지 모든 과정을 중요시해야겠다는 생각을 갖게 됐습니다.
Q. 커넥to에서 배운 내용은 개인적으로 어떻게 정리하고 있나요?
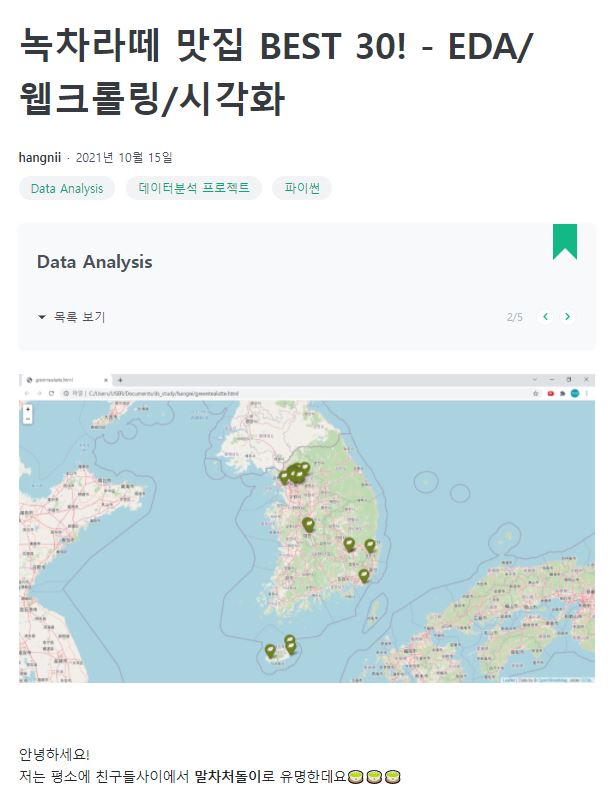
이전에는 생각만 했었는데, 커넥to에서 공부를 시작하면서 적극적으로 블로그를 활용하게 됐어요. 개인적으로 원데이 프로젝트를 하거나, 수업에서 배웠던 내용들을 다른 방식으로 적용해보기도 합니다. 예를 들어, 미국 시카고의 샌드위치 맛집 데이터를 가지고 크롤링해서 지도로 시각화했었는데요. 시카고에 갈 수 있는 게 아니니까, 이를 응용해서 녹차 맛집을 망고플레이트에 있는 정보를 바탕으로 시각화해 응용해봤습니다.
Q. 끝으로, 앞으로의 각오에 대해 들려주세요.
사실 지금은 심적으로도 체력적으로도 지친 상태예요. 하지만 이 시기를 잘 견뎌내면 끝이 나겠지요. 같은 팀원 분들이 많이 다독여주고, 붙잡아주셨어요. 할 수 있다 해주셔서 나름대로 위기를 극복하고 있습니다. 데이터 사이언스 과정을 끝까지 해내서 나와의 싸움, 그리고 취업난에서도 승리하고 싶습니다.
제로베이스 데이터 사이언스 스쿨은 데이터 취업 스쿨과 같은 과정입니다.

제로베이스와 함께한 이야기가 더 궁금하다면,
-
 커넥to에서 개념 하나하나 제대로 공부하고 있어요커넥to 수강생 TALK커넥to에는 어떤 분들이 함께하고 있을까요? 오늘 만나본 수강생은 소프트웨어 학부생 박*영님입니다. 코딩의 속도를 우선시하던 지난날과 비교해 어떻게 달라졌는지, 하루하루 어떻게 성장하고 있는지 물었습니다.
커넥to에서 개념 하나하나 제대로 공부하고 있어요커넥to 수강생 TALK커넥to에는 어떤 분들이 함께하고 있을까요? 오늘 만나본 수강생은 소프트웨어 학부생 박*영님입니다. 코딩의 속도를 우선시하던 지난날과 비교해 어떻게 달라졌는지, 하루하루 어떻게 성장하고 있는지 물었습니다. -
 실무 프로젝트, 현업 관점까지! 데이터 사이언티스트로 빠르게 성장 중입니다커넥to 수강생 TALK커넥to 데이터 사이언스, 3명의 합격자를 만나봤습니다. 전공부터 경력까지 모두 다른 세 사람은 어떻게 데이터 사이언티스트로 성장하고 있을까요?
실무 프로젝트, 현업 관점까지! 데이터 사이언티스트로 빠르게 성장 중입니다커넥to 수강생 TALK커넥to 데이터 사이언스, 3명의 합격자를 만나봤습니다. 전공부터 경력까지 모두 다른 세 사람은 어떻게 데이터 사이언티스트로 성장하고 있을까요? -
 입문자를 위한 ‘데이터 사이언스’ 산업 전망, 직무 소개!인사이트 by 제로베이스빅데이터, 데이터 분석, 머신러닝, 딥러닝… 데이터 사이언스가 궁금한 입문자라면 클릭하세요!
입문자를 위한 ‘데이터 사이언스’ 산업 전망, 직무 소개!인사이트 by 제로베이스빅데이터, 데이터 분석, 머신러닝, 딥러닝… 데이터 사이언스가 궁금한 입문자라면 클릭하세요!